
 Yazılım şirketi VNGRS, sıfırdan Türkçe için eğitilen ilk büyük dil modeli olan Kumru LLM’i tanıttı. 7.4 milyar parametreye sahip bu model, yalnızca Türkçe için önceden eğitilerek oluşturuldu ve tamamen yerel bir temel model olarak geliştirildi. Kumru’nun ana kullanım alanları arasında belge işleme, özetleme ve kurumsal soru-cevap sistemleri yer alıyor.
Yazılım şirketi VNGRS, sıfırdan Türkçe için eğitilen ilk büyük dil modeli olan Kumru LLM’i tanıttı. 7.4 milyar parametreye sahip bu model, yalnızca Türkçe için önceden eğitilerek oluşturuldu ve tamamen yerel bir temel model olarak geliştirildi. Kumru’nun ana kullanım alanları arasında belge işleme, özetleme ve kurumsal soru-cevap sistemleri yer alıyor. VNGRS, gelen taleplere göre farklı sektörlere özel modeller de eğitmeyi planlıyor. Kumru LLM, sıfırdan eğitilmiş, hafif ve kurum içi konuşlandırılabilir bir yapay zeka olarak tanımlanıyor. Bu arada model, her ne kadar Türkçe için eğitilmiş olsa da İngilizceyi ve kodlamayı da biliyor.
Tüketici sınıfı GPU’larda çalışabiliyor
 Modelin ön eğitim sürecinin 45 gün sürdüğü belirtiliyor. Bu süreçte H100 ve H200 GPU’ları üzerinde 500 GB temizlenmiş ve yinelenmemiş veriyle eğitilen model üzerinde çeşitli kullanım senaryolarına yönelik 1 milyon örnekten oluşan veri karışımıyla ince ayar (fine-tuning) gerçekleştirildi. Modelin bilgi kesim tarihi ise Mart 2024.
Modelin ön eğitim sürecinin 45 gün sürdüğü belirtiliyor. Bu süreçte H100 ve H200 GPU’ları üzerinde 500 GB temizlenmiş ve yinelenmemiş veriyle eğitilen model üzerinde çeşitli kullanım senaryolarına yönelik 1 milyon örnekten oluşan veri karışımıyla ince ayar (fine-tuning) gerçekleştirildi. Modelin bilgi kesim tarihi ise Mart 2024. Kumru’nun mimarisinin ise açık kaynak Mistral-v0.3 tabanlı olduğu belirtiliyor. Model mimarisine ek olarak toplu iş boyutu, optimize edici ve öğrenme hızı ile ilgili çeşitli tasarım kararları LLaMA-3 teknik belgesine dayanılıyor. Model, 8.192 tokenlik bağlam uzunluğuna sahip, bu da yaklaşık 20 A4 sayfasına denk gelen bir metni tek seferde işleyebileceği anlamına geliyor.
 Verimlilik odaklı tasarımı sayesinde Kumru, RTX 3090 veya RTX A4000 gibi 16 GB VRAM’li GPU’larda sorunsuz çalışabiliyor. Bu sayede yerinde konuşlandırma yapmak isteyen kurumlar için maliyet açısından da avantaj sağlıyor. VNGRS’ye göre Kumru’yu kurum içi cihazlara kurmanın maliyeti yaklaşık 2.000 dolar, oysa benzer kapasitedeki yabancı alternatiflerden Gemma-3–27B modeli için tek bir H100 GPU satın almak 30.000 dolar gerektiriyor.
Verimlilik odaklı tasarımı sayesinde Kumru, RTX 3090 veya RTX A4000 gibi 16 GB VRAM’li GPU’larda sorunsuz çalışabiliyor. Bu sayede yerinde konuşlandırma yapmak isteyen kurumlar için maliyet açısından da avantaj sağlıyor. VNGRS’ye göre Kumru’yu kurum içi cihazlara kurmanın maliyeti yaklaşık 2.000 dolar, oysa benzer kapasitedeki yabancı alternatiflerden Gemma-3–27B modeli için tek bir H100 GPU satın almak 30.000 dolar gerektiriyor. Kumru’nun açık kaynaklı daha küçük bir versiyonu da mevcut. Kumru-2B, aynı mimariyi 2 milyar parametreyle sunuyor ve yalnızca 4.8 GB bellekle çalışabiliyor. Bu sürüm, mobil cihazlarda dahi kullanılabiliyor ve Hugging Face üzerinden erişime açılmış durumda.
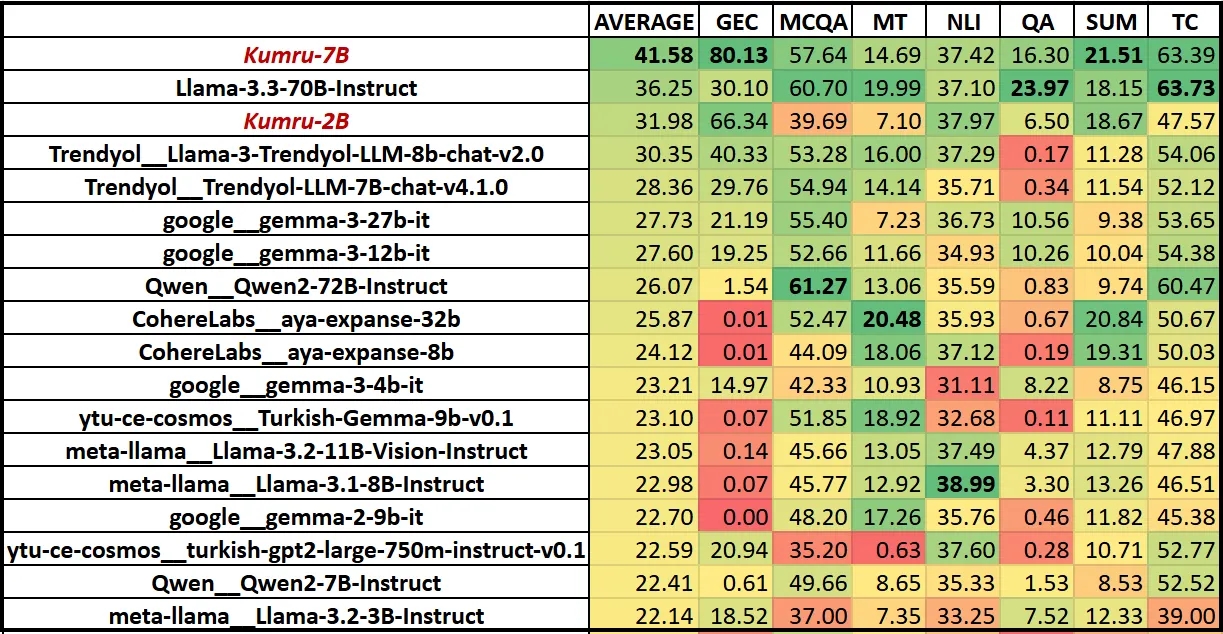
 Modelin Türkçe performansının da iddialı olduğu belirtiliyor. Yapılan testlere göre Kumru, çok daha büyük modeller olan LLaMA-3.3–70B, Gemma-3–27B, Qwen-2–72B ve Aya-32B’yi Türkçe görevlerde geride bıraktı. Özellikle dilbilgisi düzeltme ve özetleme alanlarında öne çıkan model, Türkçe’nin yapısal ve anlamsal özelliklerini daha iyi kavrıyor.
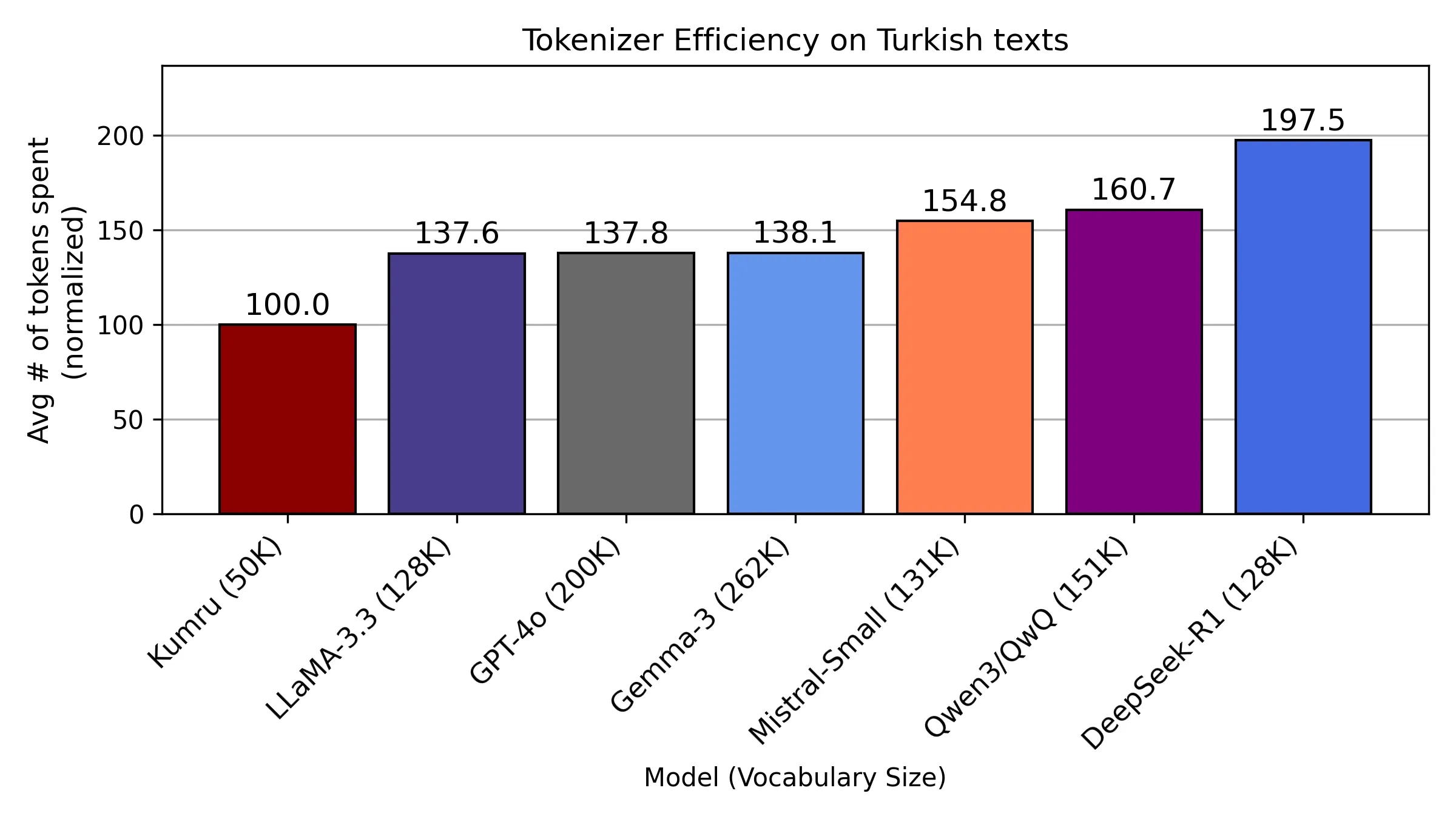
Modelin Türkçe performansının da iddialı olduğu belirtiliyor. Yapılan testlere göre Kumru, çok daha büyük modeller olan LLaMA-3.3–70B, Gemma-3–27B, Qwen-2–72B ve Aya-32B’yi Türkçe görevlerde geride bıraktı. Özellikle dilbilgisi düzeltme ve özetleme alanlarında öne çıkan model, Türkçe’nin yapısal ve anlamsal özelliklerini daha iyi kavrıyor. Kumru’nun tokenizasyon sistemi de özel olarak Türkçe için tasarlandı. Yeni RegEx tabanlı ön işlemci sayesinde satır sonları, noktalama işaretleri ve sayılar ayrı token’lar olarak işleniyor. Bu sayede model, metinleri yüzde 38 ila yüzde 98 daha az token kullanarak temsil edebiliyor. Böylece daha uzun metinleri daha hızlı ve düşük maliyetle işleyebiliyor.
Kumru’nun herkese açık demo sürümü, kumru.ai adresi üzerinden erişime açılmış durumda.


